Method: PresentAgent-2

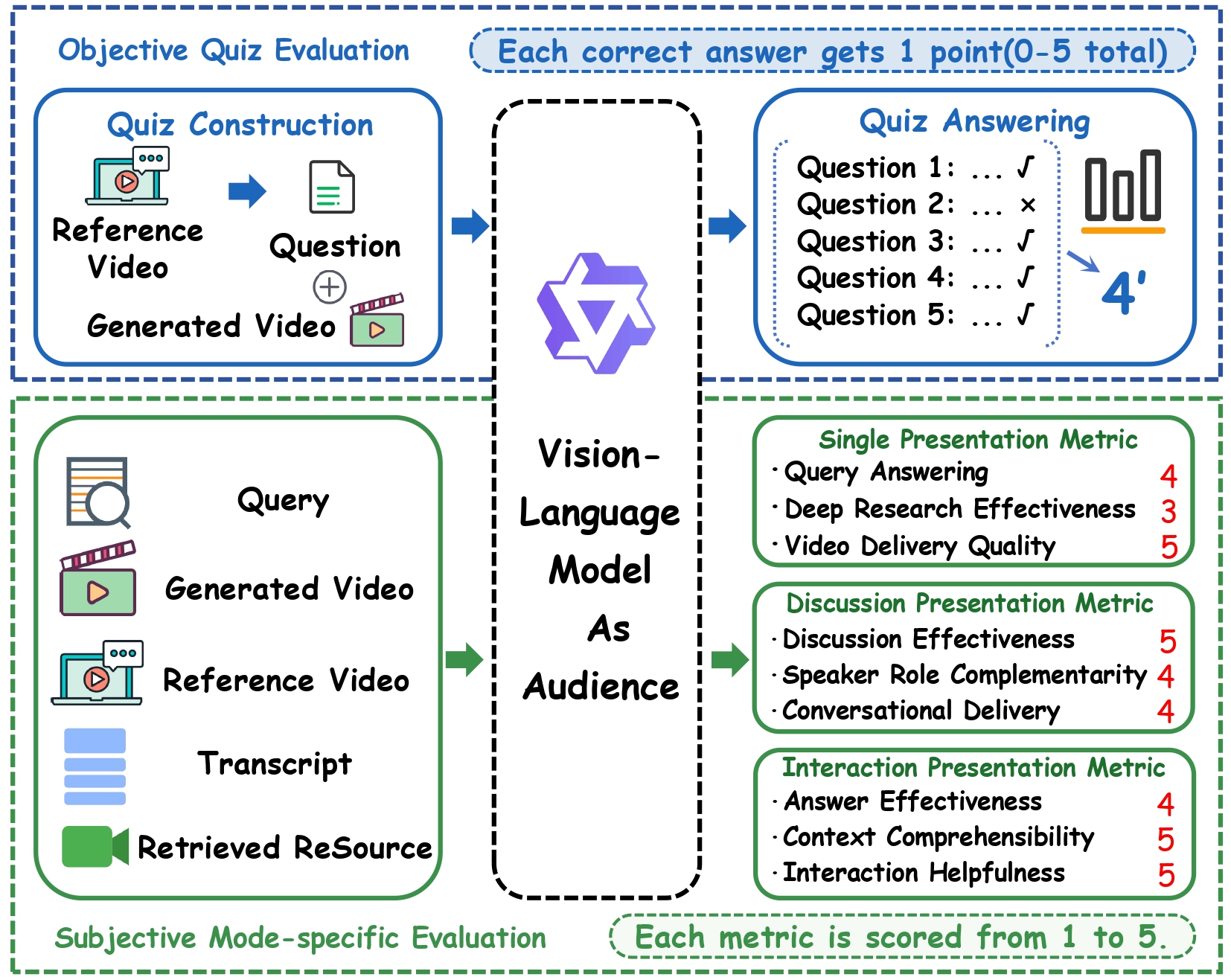
Overview of the PresentAgent-2 framework. Given a user query and a selected presentation mode, PresentAgent-2 first performs deep research to collect multimodal resources, then constructs presentation content, and finally generates a presentation video in single presentation, discussion, or interaction mode.