Real-robot deployment of MotionVLA on a Unitree G1 EDU humanoid robot.
The person walks straight ahead to the other end of the room.
The person turns and then walks to the end of the room.
The person walks straight ahead and then turns.
All qualitative motion visualizations in this paper are produced using MuJoCo, a physics engine widely used in locomotion and character animation research.
The ballerina extends her arms and turns to the left, then rises onto her toes and performs a series of ballet movements.
The man walks into the room, approaches a table, picks up an object, then walks towards a projection on the wall. He interacts with the object in his hands while standing near the projection.

Generate motion for: The person takes off a shirt and puts it on their head, then bends down to pick up something from the ground.

Generate motion for: The man walks towards the camera.
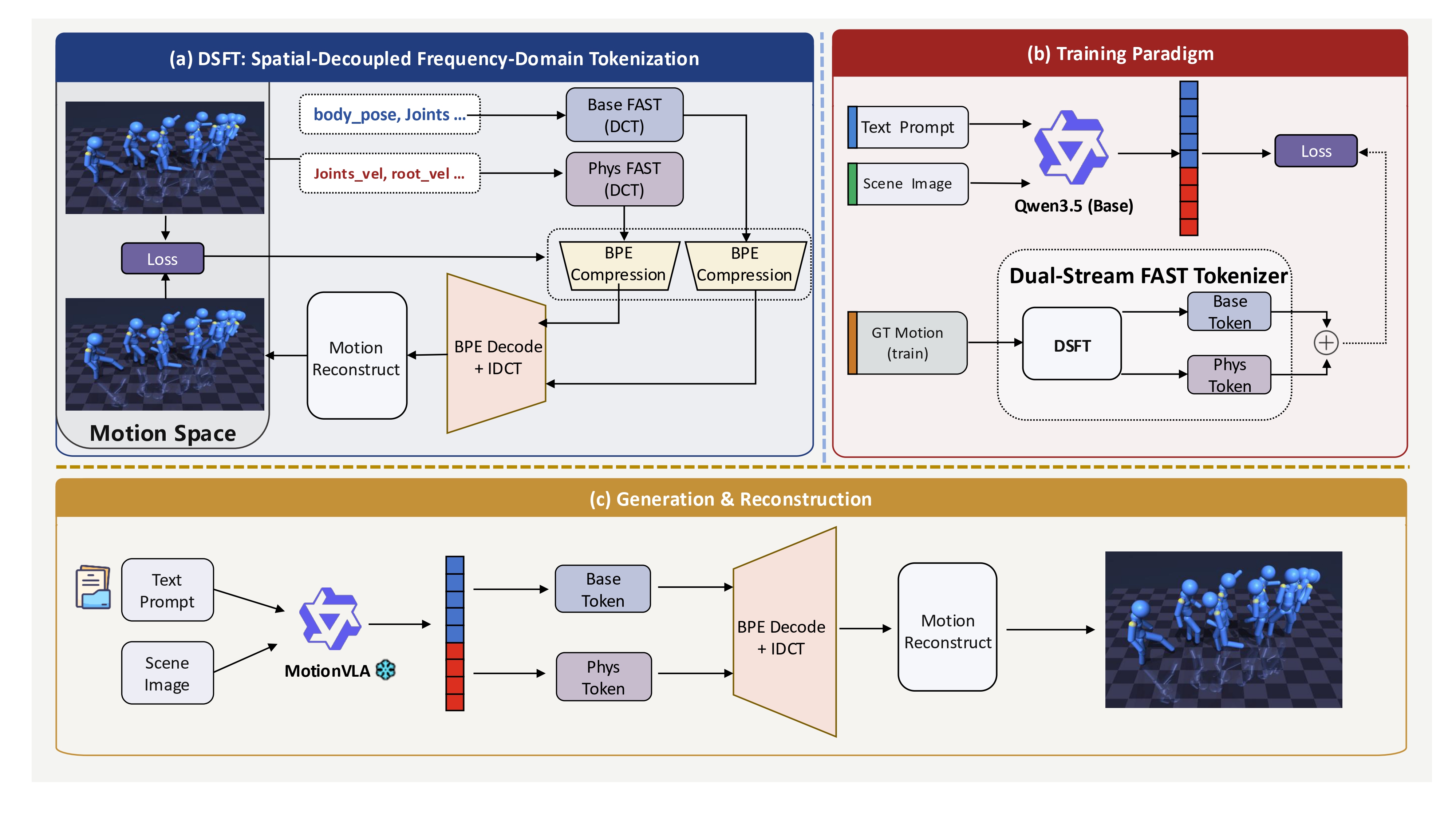
Overview of MotionVLA. (a) DSFT performs dual-stream frequency tokenization by decomposing motion into Base and Phys components and converting them into discrete tokens. (b) During training, MotionVLA learns to autoregressively predict the unified motion token sequence under text and scene-image conditioning, supervised by DSFT tokens derived from ground-truth motion. (c) At inference time, the model generates Base and Phys tokens conditioned on multimodal inputs, which are then decoded and recombined to reconstruct the final motion sequence.