Abstract
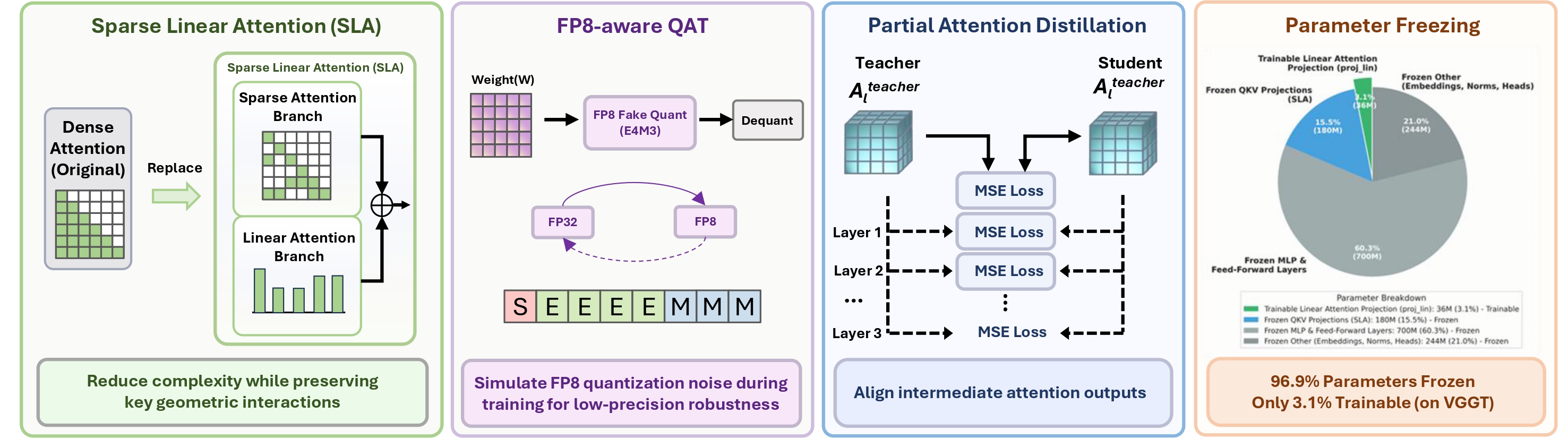
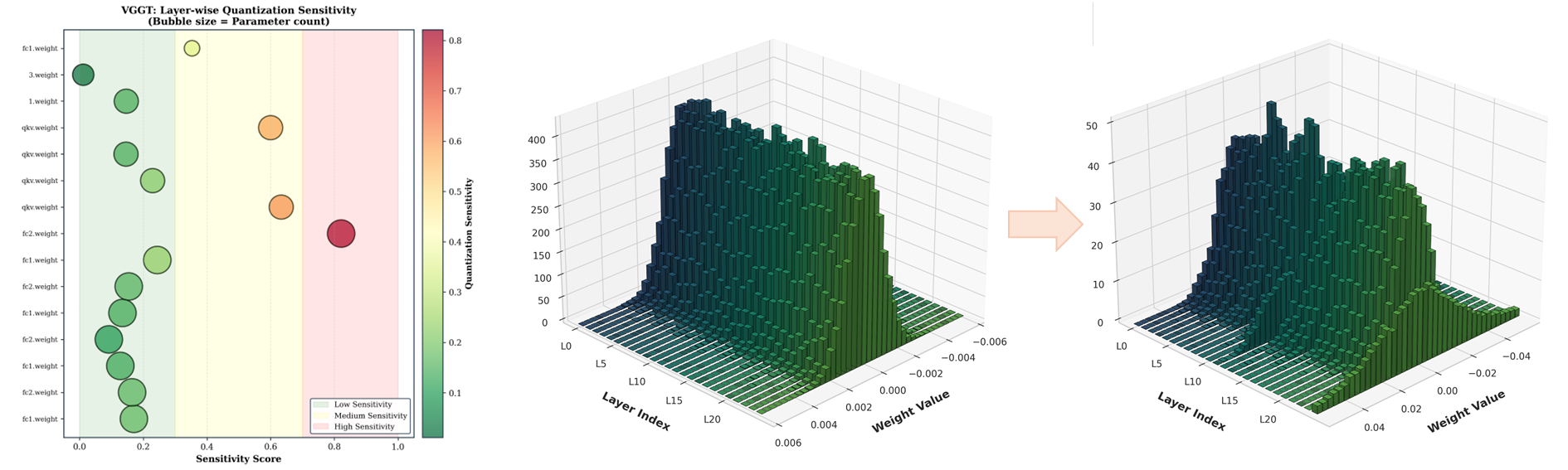
Transformer-based 3D reconstruction has emerged as a powerful paradigm for recovering geometry and appearance from multi-view observations, offering strong performance across challenging visual conditions. As these models scale to larger backbones and higher-resolution inputs, improving their efficiency becomes increasingly important for practical deployment. However, modern 3D transformer pipelines face two coupled challenges: dense multi-view attention creates substantial token-mixing overhead, and low-precision execution can destabilize geometry-sensitive representations and degrade depth, pose, and 3D consistency. To address the first challenge, we propose Lite3R, a model-agnostic teacher-student framework that replaces dense attention with Sparse Linear Attention to preserve important geometric interactions while reducing attention cost. To address the second challenge, we introduce a parameter-efficient FP8-aware quantization-aware training (FP8-aware QAT) strategy with partial attention distillation, which freezes the vast majority of pretrained backbone parameters and trains only lightweight linear-branch projection layers, enabling stable low-precision deployment while retaining pretrained geometric priors. We further evaluate Lite3R on two representative backbones, VGGT and DA3-Large, over BlendedMVS and DTU64, showing that it substantially reduces latency (1.7-2.0×) and memory usage (1.9-2.4×) while preserving competitive reconstruction quality overall. These results demonstrate that Lite3R provides an effective algorithm-system co-design approach for practical transformer-based 3D reconstruction.

BlendedMVS
Faster
BlendedMVS
Memory
Saved