Reinforcement learning has become the shiny final step in foundation-model post-training. That status is deserved, but also dangerous. Our position is simple: RL should adjust foundation models after pretraining and cold-start supervision, not be abused as the default recipe for creating capabilities from scratch.
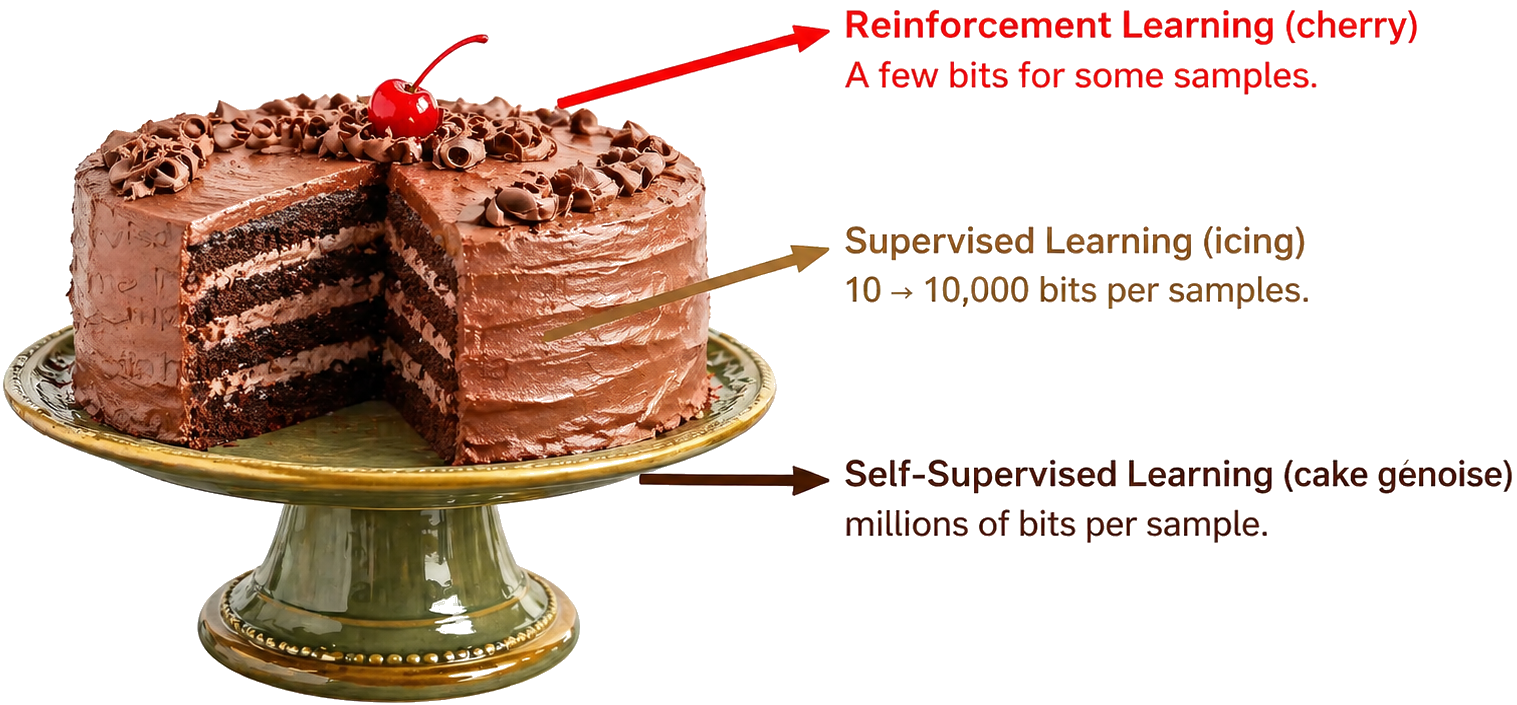
RL is powerful because it can push a model toward behaviors we can reward: correctness, constraint satisfaction, instruction following, tool-use discipline, and long-horizon consistency. But RL is also expensive and brittle. It depends on sampling, reward design, stabilization tricks, and careful evaluation. When meaningful supervision or scaffolding is available, using it first usually provides a cheaper and more stable behavior manifold for RL to refine.
The key distinction is capability creation vs. capability adjustment. Pretraining and cold-start supervision establish usable structure; RL most reliably reallocates probability mass toward better trajectories the model can already express. This is a default-practice claim, not an impossibility claim about RL-first discovery.
Five Pillars
Pillar 1
RL should be used to adjust foundation models after pretraining, particularly when a model remains unsatisfactory in certain aspects.
Across recent R1-style pipelines, RL is most useful after the model can already produce the desired behavior sometimes. It then acts as a selector and stabilizer, shifting probability mass toward more reliable, correct, and constraint-compliant trajectories.
Pillar 2
When meaningful supervised or scaffolded signals are available, they should usually precede RL.
The first-order question is not simply whether RL is expensive, but whether a meaningful scaffold exists. If it does, use it to establish a stable behavior manifold and reserve RL for residual failures; RL-first should carry a higher burden of proof.
Pillar 3
RL should not be assumed to create reasoning capability; in current foundation-model practice, it more often refines reasoning behaviors made elicitable by pretraining, SFT, or other scaffolds.
This is the core causal claim. SFT and cold-start traces can provide reasoning structure; RL improves selection, consistency, and constraint satisfaction. “RL improves reasoning” is plausible, but “RL creates reasoning from scratch” requires stronger evidence that controls for hidden scaffolds, verifier artifacts, and sampling budgets.
Pillar 4
Reward design should prioritize auditability, verifiability, and minimal composition over opaque reward complexity.
Verifiable rewards are powerful because they are externally checkable. Simple checks, tests, format constraints, and deterministic validators are easier to debug than opaque reward stacks, but even simple verifiers should be stress-tested for noise, brittleness, and proxy gaming.
Pillar 5
Self-Supervised Reinforcement Learning (SSRL) is a boundary case for structured interaction settings, not a generic replacement for pretraining or supervised scaffolding.
Self-evolution is promising when the loop is grounded in interaction, memory, and verifiable progress signals. Without those anchors, self-generated optimization can drift into self-confirming errors, unstable objectives, or reward hacking.
Why “More RL” Is Not a Strategy
The popular “RL creates reasoning” story is too coarse. RL can amplify reasoning-like behavior, and sometimes dramatically. But a stronger causal claim requires stronger evidence: compute-matched comparisons, cold-start ablations, verifier stress tests, and clear reporting of sampling budgets. Without that discipline, we risk crediting RL for structure that was actually supplied by pretraining, data curation, prompt formats, expert trajectories, or supervised traces.
Reward design is another reason to be cautious. More sophisticated rewards are not automatically safer. If the proxy is wrong, a stronger optimizer can simply exploit it more effectively. This is why we argue for reward minimalism: use checkable signals where possible, report verifier failures, and make the optimization target easy to audit.
Practical Guidelines
Before applying RL, ask four questions: Is meaningful supervision or scaffolding available? Can the model already do the behavior sometimes? Can we diagnose the failures? Can success be audited with a verifiable signal? If the answer is yes, RL is a strong adjustment tool. If not, the clearer path is often better supervision, better data, better prompting, better model specification, or a better verifier.
- Use stage discipline by default: pretraining, cold-start supervision or scaffolding, then RL adjustment.
- State falsifiable RL claims: separate the effect of RL from scaffolds, data curation, prompt formats, and verifiers.
- Make cost visible: report sampled trajectories, reward definitions, stabilizers, verifier pass rates, verifier failures, and regressions.
Call to Action
Researchers should stop treating RL as a magic capability dial. Companies and institutions should require transparency around sampling cost, reward definitions, verifier behavior, and stabilizers when RL is claimed to replace supervision. The ML community should build standards that distinguish capability creation, capability elicitation, and behavioral refinement.
The field does not need less RL. It needs more disciplined RL: staged after cold-start alignment or scaffolding when available, grounded in auditable rewards, and reported with compute transparency. RL should be the cherry, not the whole cake.